Webスクレイピング:ニュースサイトから本文を抽出する
前回まで,VOA Learning English から記事の本文を抽出しました。今回は,他のニュースサイトから記事の本文を抽出します。
段階的にURLを取得する
今回は,BBC のニュースサイトから記事の本文を抽出します。
まず,トップページのhtmlを抽出し,さらに文字列/news/を含むURLを抽出します。

次に,抽出されたURLのhtmlから次のURLを抽出します。こうして,段階的に記事のURLを取得します。
pre_extracted_urls = []
pre_extracted_urls.append('https://www.bbc.com/news')トップページのURLをリストpre_extracted_urlsに格納します。
for depth in range(2):繰り返し処理を用いて段階的に記事のURLを取得します。depthは0から1まで変化します。depthの範囲をあまりに大きくすると,処理が完了するのに非常に長い時間がかかります。
extracted_urls = []
for i in range(len(pre_extracted_urls)):
リストextracted_urlsは抽出したURLを格納します。
はじめ,pre_extracted_urlsにはトップページのURLが一つ含まれています。したがって,処理は繰り返されません。しかし,次の段階ではトップページから抽出された複数のURLを含むため,URLの数に応じて処理が繰り返されます。
try:
res = requests.get(pre_extracted_urls[i], timeout=3.0)
except Timeout:
print('Connection timeout')
continuetry:はいったん処理を実行し,例外が発生したときにexcept:を実行します。requests.get()は指定したURLからhtmlを抽出します。timeout=3.0を指定すると,アクセスしようとするサーバーから3.0秒間応答がない場合に処理を中断します。サーバーから応答が無いとき,処理が次に進まず止まってしまうことがあるので,例外処理を行うべきです。
except Timeout:はサーバーから応答が無い場合に実行されます。メッセージを表示し,continueによって繰り返し処理の最初に戻り,次の抽出を行います。
soup = BeautifulSoup(res.text, 'html.parser')
elems = soup.find_all(href=re.compile("/news/"))
print(str(len(elems))+' URLs extracted'+'('+str(i+1)+'/'+str(len(pre_extracted_urls))+')')
抽出したhtmlはres.textに格納され,それをBeutifulSoupに渡します。.find_all()は/news/を含むURLを抽出し,リストelemに格納します。
for j in range(len(elems)):
url = elems[j].attrs['href']
if not 'http' in url:
extracted_urls.append('https://www.bbc.com'+url)
else:
extracted_urls.append(url)
リストelemに格納された文字列はタグを含むため,.attrs['href']を用いてURLを抽出し文字列urlに格納します。
URLにドメイン名が含まれていない場合は,ドメイン名を加え,リストextracted_urlsに追加します。
extracted_urls = np.unique(extracted_urls).tolist()抽出された文字列は重複したURLを含みます。np.unique()は重複したデータを削除します。処理よってnumpy配列が作られるので,tolist()で通常の配列に戻し,extracted_urlsに格納します。
pre_extracted_urls = extracted_urls
urls.extend(extracted_urls)
urls = np.unique(urls).tolist()抽出されたURLを再びpre_extracted_urlsに格納します。次の繰り返し処理では,格納された複数のURLに基づいて新たなURLを抽出します。同時に,抽出されたURLをリストurlsに追加します。リストに要素を1つ追加するときには.append()を使いますが,リストのように複数の要素を追加するときには.extend()を用います。
さらに,np.unique()で重複したURLを削除します。
URLのリストから本文を抽出する
for i in range(len(urls)):
try:
res = requests.get(urls[i], timeout=3.0)
except Timeout:
print('Connection timeout')
continue
soup = BeautifulSoup(res.text, "html.parser")
リストurlsの要素数に応じて繰り返し処理を行います。
上と同じように,request.get()で記事のURLからhtmlを抽出し,BeutifulSoup()に渡します。
elems = soup.select('#page > div > div.container > div > div.column--primary > div.story-body > div.story-body__inner > p')
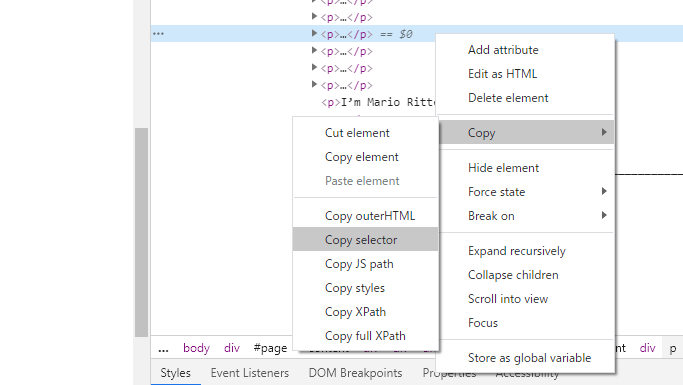
Chromeを用いてセレクタを取得できます。ブラウザに表示された本文を右クリックし,検証をクリックします。画面の右側にhtmlが表示されるので,青い線を右クリックします。さらに,Copy → Copy selector をクリックすると,クリップボードにセレクタがコピーされます。コピーされた文字列には:nth-child()が含まれていますが,これは必要ありません。
soup.select()は指定されたセレクタに含まれる文字列を抽出し,リストelemsに格納します。
if not len(elems) == 0:
for j in range(len(elems)):
texts.append(str(elems[j]))
もし,htmlが本文を含まない場合,リストelemsの要素数は0です。要素数が0でなければ,elemsの要素数に応じて繰り返し処理を行い,文字列をリストtextsに追加します。
text = ' '.join(texts)
p = re.compile(r"<[^>]*?>")
text = p.sub("", text)
text = re.sub('["“”,—]','', text)
text = text.lower()
text = text.replace('. ','\n').join()はリストtextsを一つの文字列textに結合します。
re.compile()を用いて正規表現の規則を与え,.sub()で規則に当てはまる文字列を削除します。ここでは,文字列からタグを削除します。さらに,同じ方法でダブルクォーテーションやハイフンを削除します。
.lower()は文字列を小文字に変換します。また,.replace()はピリオドを改行文字\nに変換します。
with io.open('articles_bbc.txt', 'w', encoding='utf-8') as f:
f.write(text)文字列textをテキストファイルarticles_bbc.txtに保存します。
プログラムを実行したところ,2.59MBの記事の本文が抽出されました。
全体のコードを示します。
import numpy as np
import requests
from requests.exceptions import Timeout
from bs4 import BeautifulSoup
import io
import re
urls = []
pre_extracted_urls = []
pre_extracted_urls.append('https://www.bbc.com/news')
for depth in range(2):
print('start depth: '+str(depth)+'.........................')
extracted_urls = []
for i in range(len(pre_extracted_urls)):
try:
res = requests.get(pre_extracted_urls[i], timeout=3.0)
except Timeout:
print('Connection timeout')
continue
soup = BeautifulSoup(res.text, 'html.parser')
elems = soup.find_all(href=re.compile("/news/"))
print(str(len(elems))+' URLs extracted'+'('+str(i+1)+'/'+str(len(pre_extracted_urls))+')')
for j in range(len(elems)):
url = elems[j].attrs['href']
if not 'http' in url:
extracted_urls.append('https://www.bbc.com'+url)
else:
extracted_urls.append(url)
extracted_urls = np.unique(extracted_urls).tolist()
pre_extracted_urls = extracted_urls
urls.extend(extracted_urls)
urls = np.unique(urls).tolist()
print('total: '+str(len(urls))+' URLs')
print('start extracting html....')
texts = []
for i in range(len(urls)):
try:
res = requests.get(urls[i], timeout=3.0)
except Timeout:
print('Connection timeout')
continue
soup = BeautifulSoup(res.text, "html.parser")
elems = soup.select('#page > div > div.container > div > div.column--primary > div.story-body > div.story-body__inner > p')
if not len(elems) == 0:
for j in range(len(elems)):
texts.append(str(elems[j]))
print(str(i+1)+' / '+str(len(urls))+' finished')
text = ' '.join(texts)
p = re.compile(r"<[^>]*?>")
text = p.sub("", text)
text = re.sub('["“”,—]','', text)
text = text.lower()
text = text.replace('. ','\n')
with io.open('articles_bbc2.txt', 'w', encoding='utf-8') as f:
f.write(text)
with io.open('articles_bbc.txt', 'w', encoding='utf-8') as f:
f.write(text)
SNSでシェア