Webスクレイピング:URLから記事の本文を抽出する
前回,Webスクレイピング:複数のページから記事のURLを抽出するで,VOA Learning English から記事のURLのリストを作成しました。
今回はこのリストをもとに記事の本文を抽出します。
セレクターを使用して該当箇所を取り出す
with io.open('article-url.txt', encoding='utf-8') as f:
urls = f.read().splitlines()前回,VOA Learning English から 1 か月間の記事の URL を article-url.txt に保存しました。これを読みだし,.splitlines()で行ごとに分割して url にリストとして格納します。
urls[0]='https://learningenglish.voanews.com/a/5225652.html
'
urls[1]='https://learningenglish.voanews.com/a/5225655.html'
urls[2]='https://learningenglish.voanews.com/a/5226969.html
'
・・・・・・for 文で繰り返し処理を行いながら,それぞれの URL ごとに本文のテキストを抽出します。
for i in range(len(urls)):テキストファイルに保存された URL は 199 個あるので,len(urls)=199 です。i は 0 から 198 まで変化して繰り返し処理を行います。
try:
res = requests.get(urls[i], timeout=3.0)
except Timeout:
print('Connection timeout')
continue
soup = BeautifulSoup(res.text, "html.parser")
requests.get() で html を抽出し BeutifulSoup に渡します。requests.get() は単に html を抽出する機能しか持っていないので,html を解析する BeutifulSoup にデータを渡す必要があります。
try: はいったんrequests.get()を実行し,3.0秒間サーバーから応答が無い場合に,except Timeout:を実行します。ここでは,単にcontinueでfor文のはじめに戻り,次のURLを処理します。
elems = soup.select('#article-content > div.wsw > p')コードの重要な部分です。soup.select() はセレクタを指定して,html の中の特定の部分だけを抽出し,リスト elems に格納します。
セレクタを特定する
セレクタについては HTML と CSS の知識が必要です。一般的にウェブサイトは,ヘッダーやメニュー,記事の見出し,本文,フッターなどいくつかのブロックに分かれています。それぞれのブロックは 識別するためのIDやクラスを持ち,それらに基づいてフォントや色が指定されます。こらのブロックを指定する部分をセレクタと呼んでいます。
VOA Learning English のウェブサイトでは,記事の本文を表すセレクタは #article-content > div.wsw > p です。これはHTMLでは以下のように表されます。
<div id="article-content">
<div class="wsw">
<p>本文</p>
</div>
</div> chromeブラウザを使うとセレクタを簡単に知ることができます。

記事の上でマウスを右クリックして,「検証」を選択します。
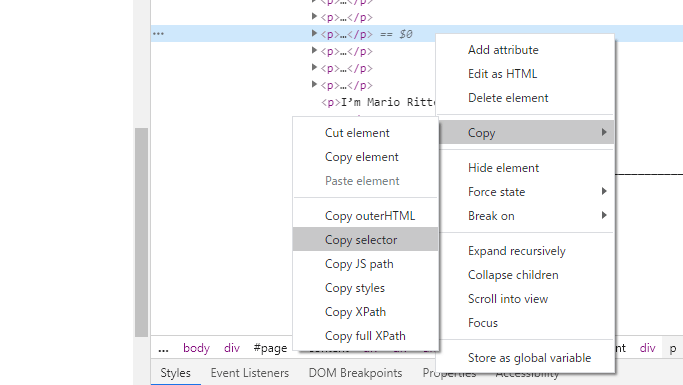
画面右側にHTMLが表示されるので,青の行をさらに右クリックします。そして,Copy → Copy selector の順にクリックすると,クリップボードにセレクタの文字列がコピーされます。
実際には,article-content > div.wsw > p:nth-child(13) のような文字列がコピーされますが,:nth-child(13) は必要ありません。
取り出した本文を結合して保存する
if not len(elems) == 0:
for j in range(len(elems)):
chars.append(str(elems[j]))
char = ' '.join(chars)
article-url.txt に抽出した URL のリストには,本文を含まないものがあります。これは本文がなく,音声のみのページが含まれるためです。指定したセレクタに該当する項目がない場合は,elems の要素数は 0 となります。
そこで,if 文を用いて要素数が 0 でない場合のみ,elems の内容を結合します。if not len(elems) == 0: は「elems の要素数が 0 でないならば」という意味です。
elems をそのままリストに追加するとあとでエラーになるので,str()で文字列にした上でリストchars に追加してきます。
また,.join()でリストcharsを一つの文字列charにまとめます。
index = char.find('_______________')
if not index == -1:
texts.append(char[:index])
else:
texts.append(char)本文の最後に単語の説明が含まれているので,それらを削除します。語句のセクションは文字列’_______________’で始まるので,これを手掛かりにします。
.find()で指定された文字列の位置を返し,indexに格納します。文字列が含まれない場合は-1を返します。
char[:index]は文字列の先頭から’_______________’の1つ前までを表します。indexが-1でないなら,単語のセクションを削除してリストtextsに追加し,indexが-1ならば,文字列をそのまま追加します。
text = ' '.join(texts)
リストtextsを1つの文字列textにまとめます。
p = re.compile(r"<[^>]*?>")
text = p.sub("", text)
抽出した本文にはタグが含まれるので,正規表現を用いてタグを削除します。re.compile()で正規表現の規則を設定し,.sub()で削除します。
text = re.sub('[“”,—]()','', text)
'[“”,—]()'のどれが一つに当てはまる文字があれば,それを削除します。
p = re.compile("\.\s+?([A-Z])")
text = p.sub(" eos \\1", text)
文末のピリオドを,文末を表す記号eosに置き換えます。ここでは,ピリオド,空白,アルファベット大文字の組を文末として判断しています。
text = text.lower()
.lower()は文字を小文字に変換します。
with io.open('articless.txt', 'w', encoding='utf-8') as f:
f.write(text)リストを結合して文字列 text を作り,ファイルarticles.txtに保存します。
article.txt の中身は以下のようになっています。
The Australian government said this week it will spend over 34 million dollars on helping wildlife recover from bushfires eos The bushfires crisis threatens several animal species, including koalas and
・・・・・・コードの全文を示します。
import numpy as np
import requests
from requests.exceptions import Timeout
from bs4 import BeautifulSoup
import io
import re
with io.open('article-url.txt', encoding='utf-8') as f:
urls = f.read().splitlines()
texts = []
for i in range(len(urls)):
try:
res = requests.get(urls[i], timeout=3.0)
except Timeout:
print('Connection timeout')
continue
soup = BeautifulSoup(res.text, "html.parser")
elems = soup.select('#article-content > div.wsw > p')
chars = []
if not len(elems) == 0:
for j in range(len(elems)):
chars.append(str(elems[j]))
char = ' '.join(chars)
index = char.find('_______________')
if not index == -1:
texts.append(char[:index])
else:
texts.append(char)
print(str(i+1)+' / '+str(len(urls))+' finished')
text = ' '.join(texts)
p = re.compile(r"<[^>]*?>")
text = p.sub("", text)
text = re.sub('[“”,—]()','', text)
p = re.compile("\.\s+?[A-Z]")
text = p.sub(" eos ", text)
text = text.lower()
with io.open('articless.txt', 'w', encoding='utf-8') as f:
f.write(text)SNSでシェア